An analysis of Kaktus Dobíječka time circumstances
Kaktus, a Czech MVNO, periodically (twice a month in most cases) organizes an happy hour event called Dobíječka, during which everyone gets their prepaid credit top-ups between 200 and 500 CZK doubled. These events are not scheduled, so one needs to be on the lookout for them, and are announced usually one or two hours before they start (among other places) on Kaktus’s website – on the “Novinky z Květináče” (“News from the flowerpot”) page to be exact. Upon closer inspection, I noticed that the announcements are written in a fairly homogeneous format, and therefore programatically processable without too much of a hassle.
Having gotten interested, I wrote a Python script to extract date and time information from them, and published it on GitHub as open-source. This blog post presents some interesting data I gathered while processing the script’s CSV output (containing a total of 135 announcements) with Excel.
Day of month
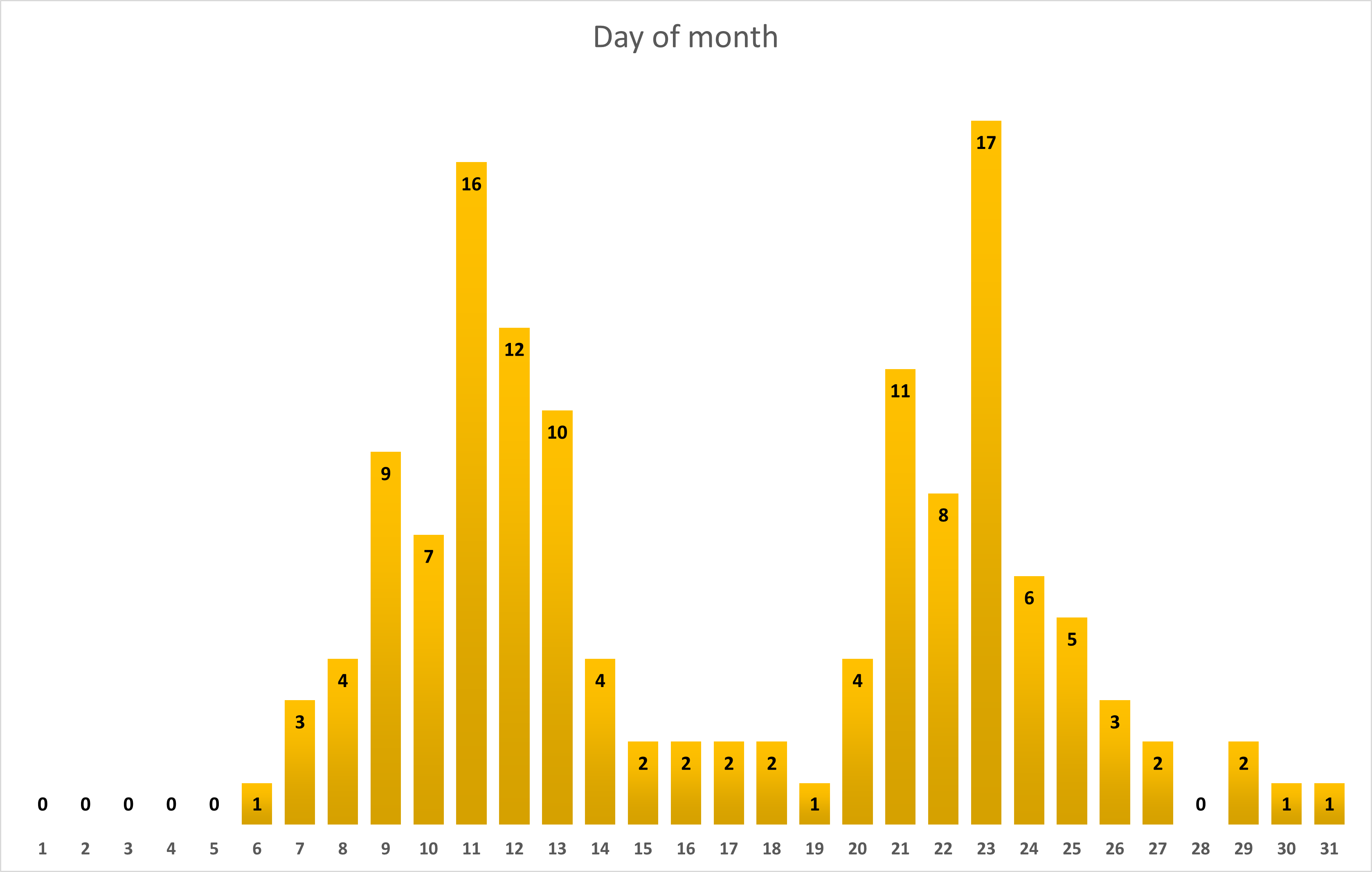
The graph clearly shows that if you are on the lookout for a Dobíječka, you could usually expect it around the 11th and 23th day of month, whereas you will be, in most cases, out of luck at the beginning, around the middle or at the end of a month.
Hour of beginning & end

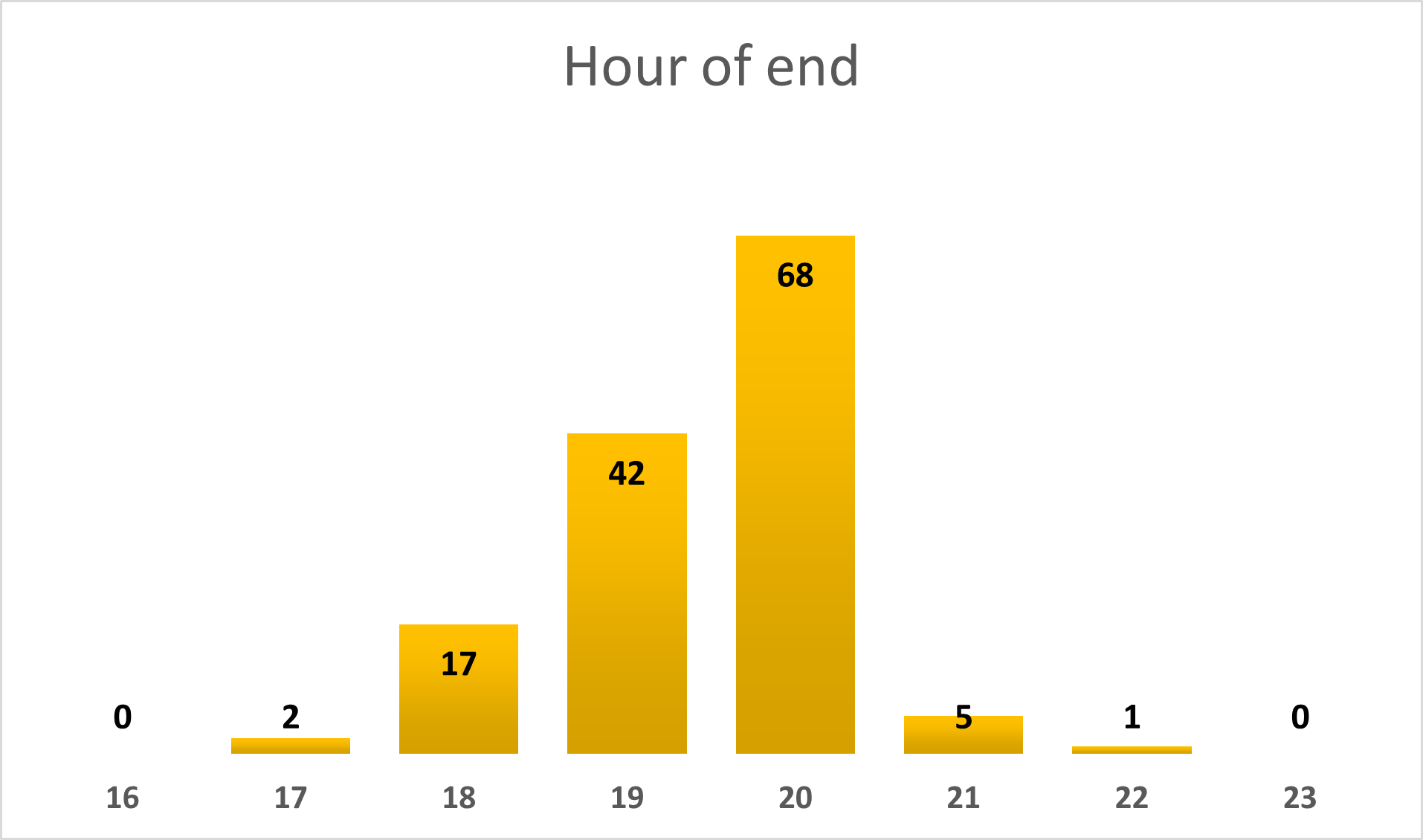
Analyzing the hour of beginning and end also did not go in vain – the resulting graphs clearly show that Dobíječkas always take place in late afternoon and early evening, and never in the morning or at night. The event begins at 17:00 (= 5 PM) in about 47% of cases, and ends at 20:00 (= 8 PM) in about 50% of cases.
There was one anomalistic Dobíječka which began at 10 AM and ended at 10 PM (= 22:00) – it was organized on 9th October 2018 in occassion of Kaktus’s 5 years anniversary.
Duration
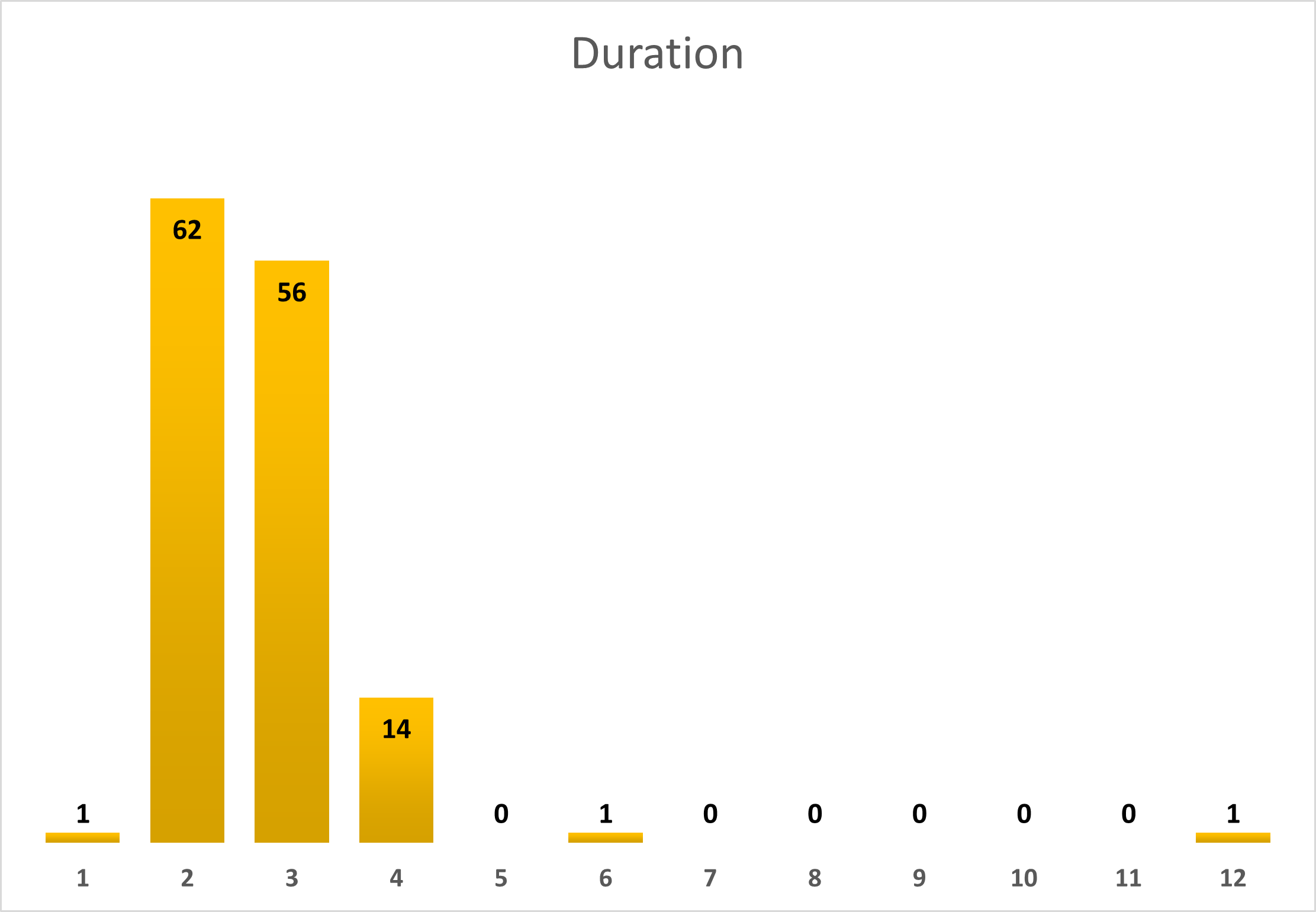
This graph shows that in about 87% of cases, Dobíječkas last 2 or 3 hours. The aforementioned 5 years anniversary Dobíječka is the one lasting 12 hours and the 6-hour-lasting one took place exactly one year after that, whereas the one-hour-lasting one took place on 18th July 2020 and nothing other than the short duration seems to be extraordinary about it.
Conclusion
This analysis confirms that even if some texts contain a lot of “noise” due to them being written to be human-readable, they might be actually parseable with a nifty Python script containing a few regular expressions, and by tinkering with the output just using something like Excel (i.e. no special data science tools needed), it might be possible to mine some interesting and useful data.
If you want to take a look at the data which I analyzed and perhaps do some more data mining, you certainly can – here are the download links:
Keep in mind that this blog post was published on 26th October 2022, and is NOT periodically updated!