Improving Tundra's speed & code quality
Over the course of the past month, I have released a multitude of new versions of Tundra, an open-source NAT64/CLAT/SIIT translator for Linux operating entirely in user-space. The versions from 4.1.6 up to 5.0.1 improved speed, memory efficiency, security and last but not least, the overall code quality of the whole translation engine, which was rewritten from the ground up. In this blog post, I would like to present the most important improvements, outline some of the thought processes I had while making them and point out some interesting traits of the rewritten parts of the program.
Balancing the load
From the very beginning, the translator was designed to be multi-threaded to fully make use of today’s modern CPUs. Originally, if the program was configured to use more than one translator thread, it created the TUN network interface for receiving and sending packets as multi-queue (by using the IFF_MULTI_QUEUE flag). Then, it acquired one file descriptor (= one packet queue) for each thread and began translating. However, this approach was severely limiting the translator’s performance, as the kernel puts packets belonging to a single connection/flow to the same queue; therefore, in case there was a single high-traffic connection going through the translator (which is quite common, at least on small home networks), it was translated only by a single translator thread, while all the other threads stayed dormant.
To tackle this issue, it was necessary to make the kernel load-balance the traffic between all of the program’s threads. Despite not being quite sure about the outcome, I decided to try initializing the TUN interface as single-queue (by default; a configuration option to revert to the old behaviour has been introduced – io.tun.multi_queue) and giving the same file descriptor referring to it to all threads.
This change was unfortunately not just a matter of making a little modification to the program’s initialization process – it required rewriting the whole thread termination mechanism to be reliant on POSIX signals instead of an anonymous pipe and a poll() call. This involved minimizing the likelihood of various race conditions occurring and creating wrapper functions for all interruptible syscalls used by the threads which are able to deal with the EINTR error. I am not going to go into any further detail here, but if you wish to explore the changes yourself, see this commit.
So, does the translator now do proper load-balancing and have the speeds improved? The answer to both of these questions is yes! Take a look at the following two screenshots:

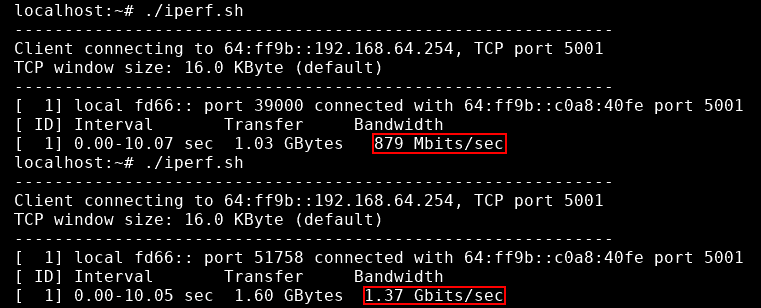
Rewriting the translation engine
Every piece of software written “on the first attempt” is far from perfect, and the old packet translation engine of Tundra was no exception – its design was laid out after reading the RFC 7915 standard and not after going through the code of an already existing NAT64 translator (such as Tayga; partly due to licensing reasons, but I also wanted to make the design “original”, i.e. without another project’s influence). For this reason, I still think that I did a fairly good job, as the translator was working without (apparent) issues and/or crashes, but this did not change the fact that the code had some severe issues mainly related to its readability and maintainability.
The original packet translation engine revolved around a per-thread triplet of continuous packet buffers – in_packet, out_packet and tmp_packet (used when fragmenting out_packet), and the problem was that the buffer for the outbound packet was written to by effectively all parts of the translation engine, which consisted of more than 1000 lines of code (I did not anticipate such length of the code when laying out the initial design), and therefore essentially behaving as a global variable. As is now apparent, keeping track of the buffers’ contents and ensuring their consistency at all times was difficult to say the least, although it seems that nothing ended up broken, as mentioned above.
When thinking of how to rewrite the engine for it to be better, I remembered that (not only) Linux offers the writev() syscall, which accepts multiple buffers of data instead of only a single one. This made it possible to leave the “one huge buffer for the whole outbound packet” approach I used previously – instead, I let each “unit of code” construct its own small buffer for its part of the translated data. Not only was it now clear what part of code writes to which part of memory, but also possible to not copy the whole payload of all packets, since the translator only needs to modify IP headers and transport layer headers and not the data which come after them.
All things considered, the new translator’s code is more maintainable, readable and understandable, which makes it more secure. It also uses a few kilobytes less memory, as it only allocates a single buffer (for inbound packets) instead of three, and seems to be a bit faster, probably due to its aforementioned zero-copy approach. One interesting trait of it is its behaviour when fragmenting packets – the transport layer header buffer and the payload buffer are fragmented separately:

Unfortunately, this behaviour, which was not present in the “original” translation engine, has one annoying consequence: the size of the transport layer header buffer, which is sent before the payload one, has to be a multiple of 8, as the fragment offset field in IPv4/v6 packets specifies the offset in 8-byte units. This makes some parts of the code more complicated, notably the code translating TCP headers, which are 20 bytes in size (not a multiple of 8).
Final words
The changes along with the versions they were introduced in are recoded in the project’s CHANGELOG, and if they are interesting to you and you wish to explore them in more detail, you certainly can – as has been said, the project is open-source and the source code is located in the vitlabuda/tundra-nat64 GitHub repository!